This Christmas I asked Santa for a Brultech ECM-1240 whole home energy monitoring system, specifically the DUO-100 package. After reviewing various products, I really liked that this one was priced quite reasonably for the hardware, and that they published the communication protocol.
You (or a licensed electrian) install the ECM-1240 at your main electrical panel. Each ECM-1240 has 7 channels. In my case, the first channel on the first unit measures the incoming main line current. For the other 13 channels you are free to choose various circuits from your panel that you want to monitor. You can gang various circuits together into a single channel if you like (all lighting loads, for example). The device uses current transformers on each circuit for the monitoring. These are installed inside the panel. The hot wire coming out of each breaker has to go through a current transformer, so this isn’t a simple plug-in installation; there is wiring to be done.
The company distributes software for the device for free, or you can choose from various 3rd party software. Alternatively you can configure the device to send data to websites.
I’m not a fan of sending my home energy data to someone else’s server. Apart from being a huge privacy concern (it’s pretty easy to see when you’re home, and when you went to bed), I don’t want to pay a monthly fee, and I don’t want to worry about how to get my data from their server if they go out of business or decide to discontinue their product. For those reasons, I installed their software. It’s basically a flash website that I hosted on our Windows Home Server, which is conveniently the computer hooked up to the ECM-1240’s as well.
At first their software worked quite well, but over time it started to show problems. After just less than 2 months of logging, the flash program was so sluggish to load a page that it took over 2 minutes to refresh a screen. Admittedly I was running it on an older PC. Additionally, in that amount of time it had already logged about 680 MB of data. That seemed excessive. It also logged to a SQL Lite database (a single-user file-based database), and unfortunately kept the database file locked all the time. The website would end up locking the database and packets started getting buffered in the logging software until you closed down the website and released the lock.
I decided I’d just write my own software:
I’m a C# developer, so that was my language of choice. If you’re a .NET developer too, I’ll include a link to my source code at the end of this post. Note that this software isn’t commercial quality. It’s semi-configurable (channel names, and so on) but it assumes you have a 14 channel system where the first channel is the main panel input. If your system is different, you’ll have to make some modifications.
These devices I purchased use a serial port for communication, but they give you an RS232 splitter cable so you only have to use up one serial port on your PC. Their software relies on putting the device into an automatic send mode… the device itself chooses when to send packets. If the load changes significantly on one of the circuits, it triggers an immediate packet send. Unfortunately with 2 devices on the same RS232 port, you can sometimes get a collision. Their software deals with this by detecting it and ignoring the data, but I had a sneaking suspicion that once in a rare while, it ended up getting a corrupt packet, and there was at least one point where their software logged an extremely high energy reading, and it didn’t make any sense. Therefore I wrote my software to use a polling mode. It requests data from the first device, waits about 5 seconds, requests it from the other device, waits 5 seconds, and repeats. On average we get one reading about every 10 seconds from each device. Testing seemed to indicate this was about as fast as I could go because there was a reset period after you talked to one device where you had to wait for it to time out before you could address the other one. In retrospect, if you just hooked them up to 2 separate serial ports you could probably poll the data faster.
Next I had to choose how to log the data. I really wanted the data format to be compact, but I still wanted decently small time periods for each “time slice”. I also didn’t want to be locking the file constantly, so I just wanted to be able to write the data for each time slice, and be done with it. I settled on a binary format with fixed length records. Here’s how it works: each day’s data is stored in a separate file, so the data for April 1st is stored in a file called 2015-04-01.dat. The device generates values in watt-seconds. I calculated that at a maximum current of 200A (100A panel x 2 legs) x 120V, then in a 10 second time slice I should log a maximum of 240,000 watt-seconds. A 20-bit number (2.5 bytes) can store a maximum value of 1,048,575. I didn’t want to go smaller than half-byte increments. So, 14 channels at 2.5 bytes per channel gave me 35 bytes for each 10 second time slice, and since the devices generate voltage I figured I’d log the voltage as a 36’s byte just to make it an even number. Using those numbers, running 24 hours a day for 365 days a year, this will use up under 110 MB/year. Not bad. A flat binary file like this is also fast for data access. The data is small, and seeking a time slice can be done in O(1) time. After you find the first time slice you just keep reading bytes sequentially until you get to the end of the file or your last time slice. Hopefully no more 2 minute load times.
I broke up my application into multiple programs. The first is a utility program called Uploader.exe. This is a command line program that reads the data from a device and just spits it out to the screen. Useful for testing if it works.
The second is called Logger.exe and it does just that. It uses Uploader.exe to read values from the two ECM-1240 units at 5 second offsets and writes the data to XML files into a PacketLog folder. Each file has the timestamp of when it was read, and the device number to indicate which device it came from.
The third program is called PacketProcessor.exe. This program monitors the PacketLog folder and waits until it has at least one packet from each device after the end of the current time slice it’s trying to build. If it does, it calculates the values for the current time slice and appends it to the end of the current day’s data file. It then deletes any unnecessary packets from the PacketLog folder (it keeps at most one packet from each device before the end of the most recently written time slice).
To host Logger.exe and PacketProcessor.exe, I used nssm a.k.a. “the Non-Sucking Service Manager”. It’s a small command line program you can use to run another command line program as a service. Very handy.
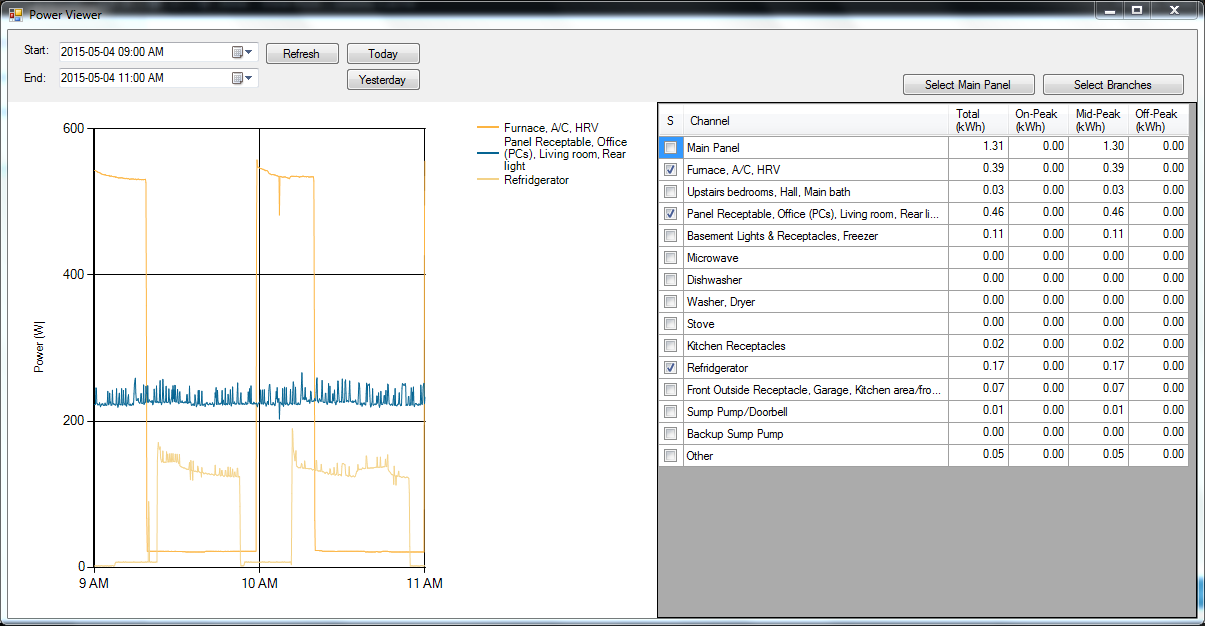
The fourth program is called Viewer.exe. It’s the graphical interface for viewing the power data. Here’s a screenshot of data from one day (just the main panel power, click on it to make it bigger):
That’s a rather typical day. The big spike around 5 pm is the oven, and you can see the typical TV-watching time is after 8 pm once the kids are in bed. On the right you can see it breaks out the power usage in kWh for each channel, and in our area we have time-of-use billing, and this actually breaks the power usage out into off-peak, mid-peak, and on-peak amounts.
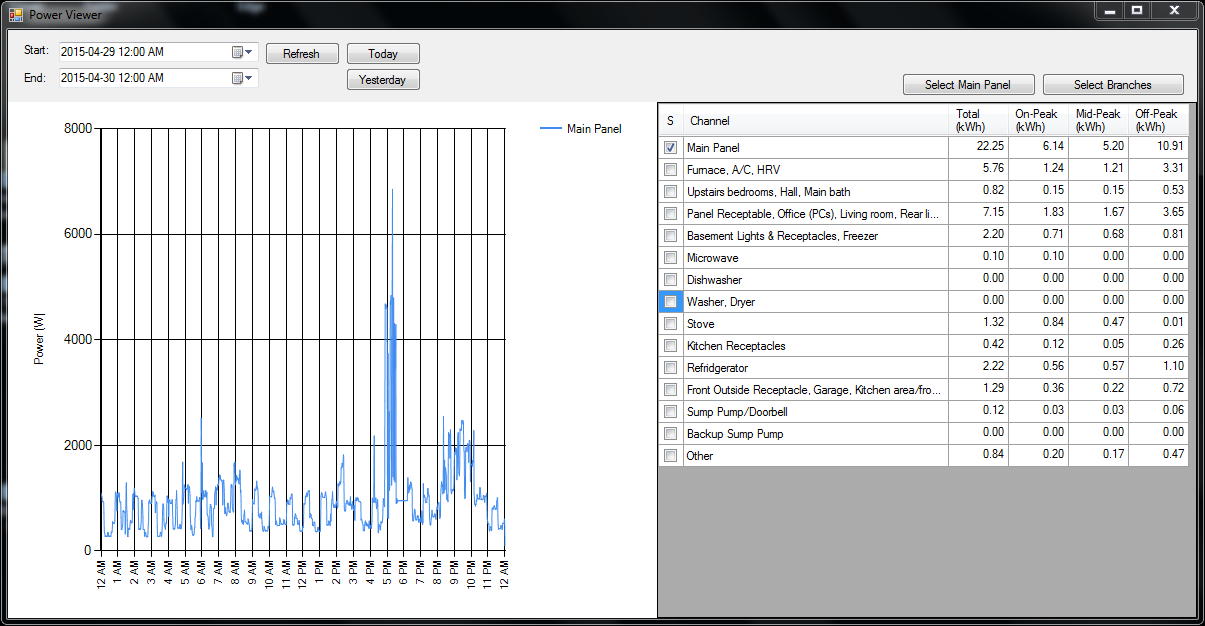
The viewer program uses a line graph for all time periods under 24 hours, but switches to an hourly bar graph for periods longer than that. Here is a 48-hour time period, and I’ve changed from just the Main Panel to all the branch circuit channels instead:
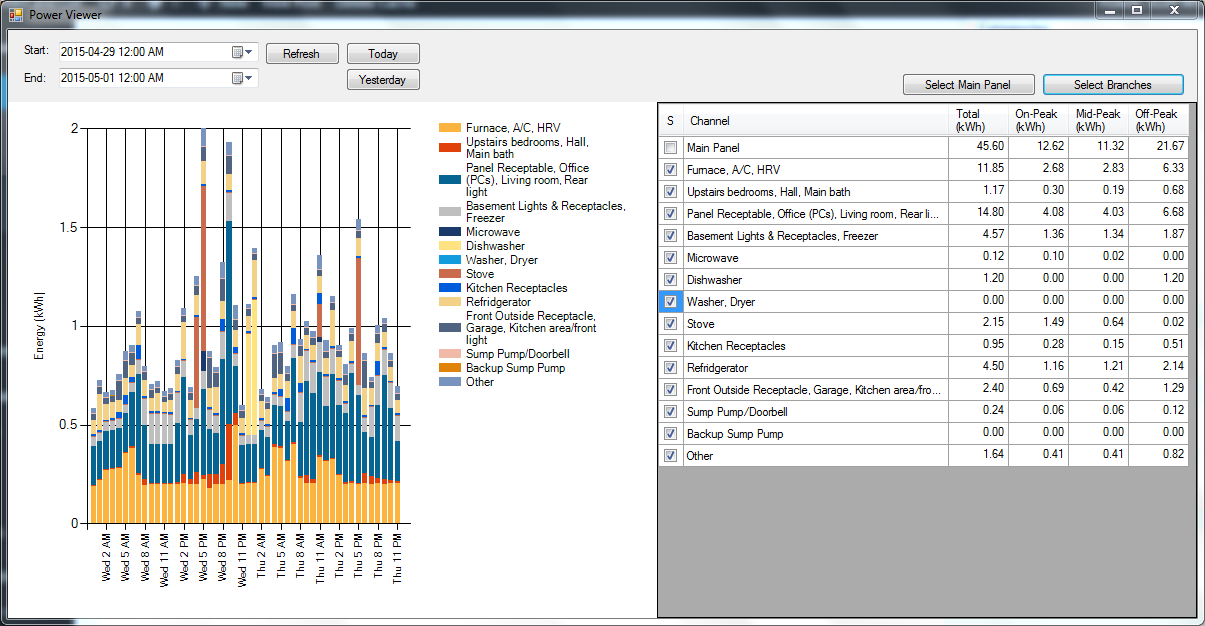
If you ask for a time period of more than a week it switches into daily bars:
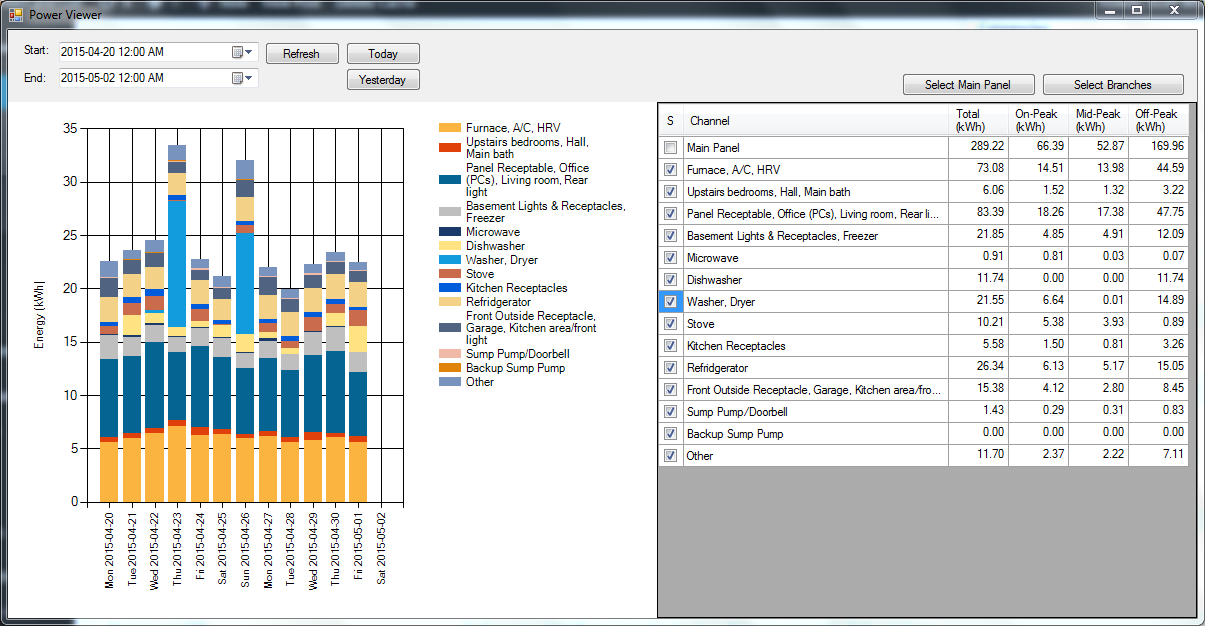
Pulling up two weeks of data like that was actually very fast, just a few seconds.
One final feature I added was email alerts. One of the channels monitors just my backup sump pump circuit. If it ever turns on, that’s because my main sump pump has failed, and I want to know. Through a configuration file, I configured an alarm to email me if that circuit ever records more than 5W of power in a 10 second time slice. I did a little test and it works (it does require that you have a Gmail account though).
Here’s the source code, if you’re interested:
As always, feel free to email me if you have questions or comments.


