PC programming and PLC programming are radically different paradigms. I know I’ve talked about this before, but I wanted to explore something that perplexes me… why do so many PC programmers hate ladder logic when they are first introduced to it? Ladder logic programmers don’t seem to have the same reaction when they’re introduced to a language like VB or C.
I mean, PC programmers really look down their noses at ladder logic. Here’s one typical quote:
Relay Ladder Logic is a fairly primitive langauge. Its hard to be as productive. Most PLC programmers don’t use subroutines; its almost as if the PLC world is one that time and software engineering forgot. You can do well by applying simple software engineering methods as a consequence, e.g., define interfaces between blocks of code, even if abstractly.
I’m sorry, but I don’t buy that. Ladder logic and, say C#, are designed for solving problems in two very different domains. In industrial automation, we prefer logic that’s easy to troubleshoot without taking down the system.
In the world of C#, troubleshooting is usually done in an offline environment.
My opinion is that Ladder Logic looks a lot like “polling” and every PC programmer knows that polling is bad, because it’s an inefficient use of processor power. PC programmers prefer event-driven programming, which is how all modern GUI frameworks react to user-initiated input. They want to see something that says, “when input A turns on, turn on output B”. If you’re familiar with control systems, your first reaction to that statement is, “sure, but what if B depends on inputs C, D, and E as well”? You’re right – it doesn’t scale, and that’s the first mistake most people make when starting with event-driven programming: they put all their logic in the event handlers (yeah, I did that too).
Still, there are lots of situations where ladder logic is so much more concise than say, C#, at implementing the same functionality, I just don’t buy all the hate directed at ladder logic. I decided to describe it with an example. Take this relatively simple ladder logic rung:

What would it take to implement the same logic in C#? You could say all you really need to write is D = ((A && B) || D) && C; but that’s not exactly true. When you’re writing an object oriented program, you have to follow the SOLID principles. We need to separate our concerns. Any experienced C# programmer will say that we need to encapsulate this logic in a class (let’s call it “DController” – things that contain business logic in C# applications are frequently called Controller or Manager). We also have to make sure that DController only depends on abstract interfaces. In this case, the logic depends on access to three inputs and one output. I’ve gone ahead and defined those interfaces:
public interface IDiscreteInput
{
bool GetValue();
event EventHandler InputChanged;
}
public interface IDiscreteOutput
{
void SetValue(bool value);
}
Simple enough. Our controller needs to be able to get the value of an input, and be notified when any input changes. It needs to be able to change the value of the output.
In order to follow the D in the SOLID principles, we have to inject the dependencies into the DController class, so it has to look something like this:
internal class DController
{
public DController(IDiscreteInput inputA,
IDiscreteInput inputB, IDiscreteInput inputC,
IDiscreteOutput outputD)
{
}
}
That’s a nice little stub of a class. Now, as an experienced C# developer, I follow test-driven development, or TDD. Before I can write any actual logic, I have to write a test that fails. I break open my unit test suite, and write my first test:
[TestMethod]
public void Writes_initial_state_of_false_to_outputD_when_initial_inputs_are_all_false()
{
var mockInput = MockRepository.GenerateStub<IDiscreteInput>();
mockInput.Expect(i => i.GetValue()).Return(false);
var mockOutput = MockRepository.GenerateStrictMock<IDiscreteOutput>();
mockOutput.Expect(o => o.SetValue(false));
var test = new DController(mockInput, mockInput, mockInput, mockOutput);
mockOutput.VerifyAllExpectations();
}
Ok, so what’s going on here? First, I’m using a mocking framework called Rhino Mocks to generate “stub” and “mock” objects that implement the two dependency interfaces I defined earlier. This first test just checks that the first thing my class does when it starts up is to write a value to output D (in this case, false, because all the inputs are false). When I run my test it fails, because my DController class doesn’t actually call the SetValue method on my output object. That’s easy enough to remedy:
internal class DController
{
public DController(IDiscreteInput inputA, IDiscreteInput inputB,
IDiscreteInput inputC, IDiscreteOutput outputD)
{
if (outputD == null) throw new ArgumentOutOfRangeException("outputD");
outputD.SetValue(false);
}
}
That’s the simplest logic I can write to make the test pass. I always set the value of the output to false when I start up. Since I’m calling a method on a dependency, I also have to include a guard clause in there to check for null, or else my tools like ReSharper might start complaining at me.
Now that my tests pass, I need to add some more tests. My second test validates when my output should turn on (only when all three inputs are on). In order to write this test, I had to write a helper class called MockDiscreteInputPatternGenerator. I won’t go into the details of that class, but I’ll just say it’s over 100 lines long, just so that I can write a reasonably fluent test:
[TestMethod]
public void Inputs_A_B_C_must_all_be_true_for_D_to_turn_on()
{
MockDiscreteInput inputA;
MockDiscreteInput inputB;
MockDiscreteInput inputC;
MockDiscreteOutput outputD;
var tester = new MockDiscreteInputPatternGenerator()
.InitialCondition(out inputA, false)
.InitialCondition(out inputB, false)
.InitialCondition(out inputC, false)
.CreateSimulatedOutput(out outputD)
.AssertThat(outputD).ShouldBe(false)
.Then(inputA).TurnsOn()
.AssertThat(outputD).ShouldBe(false)
.Then(inputB).TurnsOn()
.AssertThat(outputD).ShouldBe(false)
.Then(inputA).TurnsOff()
.AssertThat(outputD).ShouldBe(false)
.Then(inputC).TurnsOn()
.AssertThat(outputD).ShouldBe(false)
.Then(inputB).TurnsOff()
.AssertThat(outputD).ShouldBe(false)
.Then(inputA).TurnsOn()
.AssertThat(outputD).ShouldBe(false)
.Then(inputB).TurnsOn()
.AssertThat(outputD).ShouldBe(true); // finally turns on
var test = new DController(inputA, inputB, inputC, outputD);
tester.Execute();
}
What this does is cycle through all the combinations of inputs that don’t cause the output to turn on, and then I finally turn them all on, and verify that it did turn on in that last case.
I’ll spare you the other two tests. One check that the output initializes to on when all the inputs are on initially, and the last test checks the conditions that turn the output off (only C turning off, with A and B having no effect). In order to get all of these tests to pass, here’s my final version of the DController class:
internal class DController
{
private readonly IDiscreteInput inputA;
private readonly IDiscreteInput inputB;
private readonly IDiscreteInput inputC;
private readonly IDiscreteOutput outputD;
private bool D; // holds last state of output D
public DController(IDiscreteInput inputA, IDiscreteInput inputB,
IDiscreteInput inputC, IDiscreteOutput outputD)
{
if (inputA == null) throw new ArgumentOutOfRangeException("inputA");
if (inputB == null) throw new ArgumentOutOfRangeException("inputB");
if (inputC == null) throw new ArgumentOutOfRangeException("inputC");
if (outputD == null) throw new ArgumentOutOfRangeException("outputD");
this.inputA = inputA;
this.inputB = inputB;
this.inputC = inputC;
this.outputD = outputD;
inputA.InputChanged += new EventHandler((s, e) => setOutputDValue());
inputB.InputChanged += new EventHandler((s, e) => setOutputDValue());
inputC.InputChanged += new EventHandler((s, e) => setOutputDValue());
setOutputDValue();
}
private void setOutputDValue()
{
bool A = inputA.GetValue();
bool B = inputB.GetValue();
bool C = inputC.GetValue();
bool newValue = ((A && B) || D) && C;
outputD.SetValue(newValue);
D = newValue;
}
}
So if you’re just counting the DController class itself, that’s approaching 40 lines of code, and the only really important line is this:
bool newValue = ((A && B) || D) && C;
It’s true that as you wrote more logic, you’d refactor more and more repetitive code out of the Controller classes, but ultimately most of the overhead never really goes away. The best you’re going to do is develop some kind of domain specific language which might look like this:
var dController = new OutputControllerFor(outputD)
.WithInputs(inputA, inputB, inputC)
.DefinedAs((A, B, C, D) => ((A && B) || D) && C);
…or maybe…
var dController = new OutputControllerFor(outputD)
.WithInputs(inputA, inputB, inputC)
.TurnsOnWhen((A, B, C) => A && B && C)
.StaysOnWhile((A, B, C) => C);
…and how is that any better than the original ladder logic? That’s not even getting into the fact that you wouldn’t be able to use breakpoints in C# when doing online troubleshooting. This code would be a real pain to troubleshoot if the sensor connected to inputA was becoming flaky. With ladder logic, you can just glance at it and see the current values of A, B, C, and D.
Testing: the C# code is complex enough that it needs tests to prove that it works right, but the ladder logic is so simple, so declarative, that it’s obvious to any Controls Engineer or Electrician exactly what it does: turn on when A, B, and C are all on, and then stay on until C turns off. It doesn’t need a test!
Time-wise: it took me about a minute to get the ladder editor open and write that ladder logic, but about an hour to put together this C# example in Visual Studio.
So, I think when someone gets a hate on for ladder logic, it just has to be fear. Ladder logic is a great tool to have in your toolbox. Certainly don’t use ladder logic to write an ERP system, but do use it for discrete control.

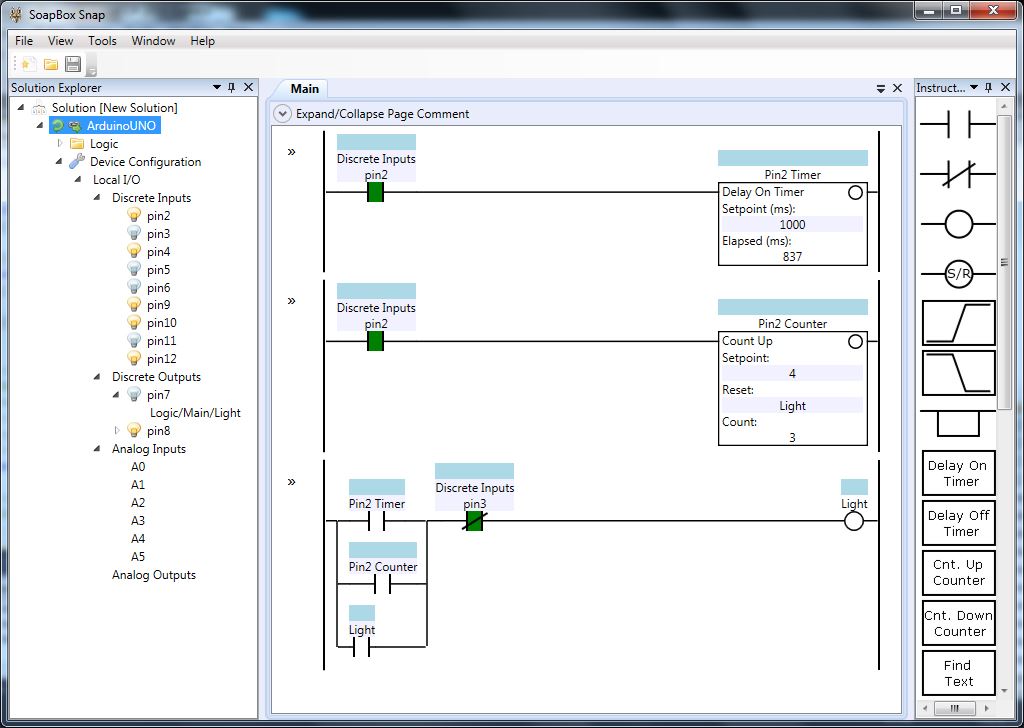

![Ladder logic defining C[1] as a function of A, B, and C[0]](http://www.contactandcoil.com/wp-content/uploads/ABC0C1.png "ABC0C1")




{kind=link}